Alibaba Qwen-Image-2.0 delivers 2K image synthesis ten times faster than standard models
Alibaba’s efficient new architecture delivers high-resolution 2K imagery and precise typography while slashing generation times for production-ready utility.
May 14, 2026
Alibaba Cloud’s release of the Qwen-Image-2.0 technical report marks a pivotal shift in the trajectory of generative artificial intelligence, moving the industry away from purely aesthetic experimentation and toward high-velocity, production-ready utility.[1] The model represents a substantial overhaul of the previous Qwen-Image framework, prioritizing architectural efficiency, training stability, and a unified approach to image generation and editing.[1] By doubling the spatial compression ratio compared to industry standards and reducing the required denoising steps by a factor of ten, Alibaba has created a system that reconciles the traditionally opposing forces of visual fidelity and computational speed. This development suggests a future where high-resolution image synthesis is no longer a resource-intensive bottleneck but a lightweight, integrated component of broader multimodal workflows.[1]
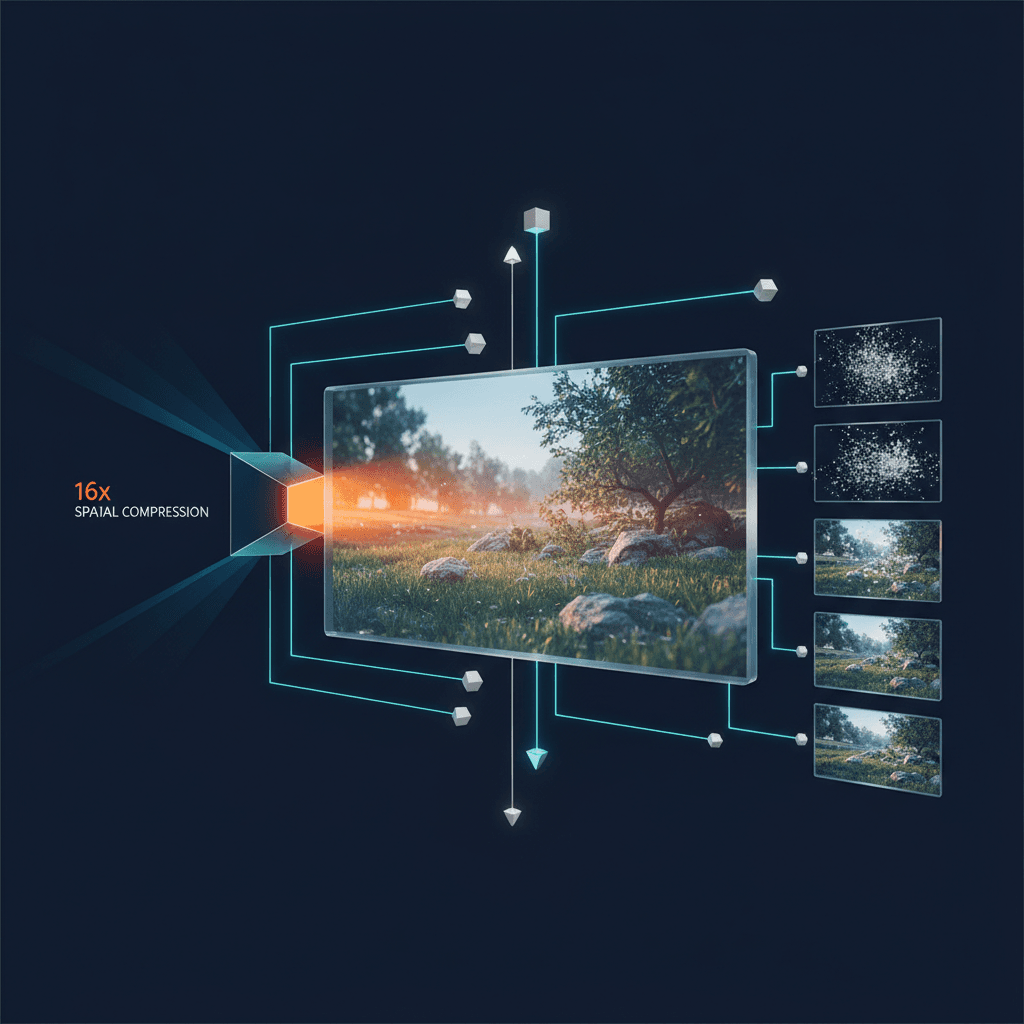
At the heart of Qwen-Image-2.0 is a Multimodal Diffusion Transformer architecture that utilizes a two-stream approach to process conditioning signals and visual targets.[2][1][3] The system employs an 8-billion parameter Qwen3-VL model as its condition encoder, which interprets user instructions and any provided reference images.[1] This is paired with a 7-billion parameter diffusion decoder, a significant reduction from the 20-billion parameter count of its predecessor.[1][4] Despite this smaller footprint, the model achieves superior performance through an aggressive spatial compression strategy implemented in its variational auto-encoder.[3] While most contemporary models, such as Stable Diffusion XL or Flux, utilize an 8x compression ratio to balance resolution and latency, Qwen-Image-2.0 doubles this to a 16x ratio.[1] This compression allows the model to process 2K-resolution imagery—specifically 2048 by 2048 pixels—within a highly condensed latent space, dramatically reducing the memory overhead and accelerating the training and inference cycles.
To ensure that this heavy compression does not lead to a loss of fine-grained detail, Alibaba’s engineers utilized a 64-channel configuration for the variational auto-encoder.[1] This high-dimensional representation allows the model to capture microscopic textures, such as skin pores, fabric weaves, and complex architectural surfaces, which are often blurred out in more aggressive compression schemes.[1] The technical report emphasizes that this configuration achieved higher reconstruction scores than its peers, effectively proving that architectural cleverness can compensate for reduced parameter counts. Furthermore, the model incorporates a reworked transformer block that addresses the instability issues common in large-scale diffusion training. By implementing Root Mean Square Normalization for Query-Key normalization (QK-Norm) and standard LayerNorm for other layers, the researchers were able to stabilize the gradient flow, preventing the "exploding" gradients that frequently plague high-resolution generative models.[1]
The most visible breakthrough for end-users, however, is the leap in generation speed facilitated by diffusion distillation.[1] Traditionally, high-quality diffusion models require between 30 and 50 denoising steps to move from random noise to a coherent image.[1] Qwen-Image-2.0 offers a full version that operates at 40 steps for maximum precision, but the technical report introduces a distilled variant that requires just four denoising steps to produce nearly identical results.[1] This 10x reduction in sampling evaluations is achieved through a distillation process where a student model learns to approximate the trajectory of a complex teacher model. For enterprise applications, this shift is transformative; it reduces the cost per image and enables near-instantaneous feedback loops in creative software, effectively bringing AI image generation into the realm of real-time interaction.[1]
Beyond raw speed, Alibaba has focused on the intelligence of the interface through a dedicated prompt expansion module.[5] One of the persistent challenges in image generation is the "prompt gap," where users provide short, vague descriptions that the AI fails to interpret with sufficient detail.[1] Qwen-Image-2.0 solves this by integrating a module that automatically expands a simple three-word query into a rich, structured instruction of up to 1,000 tokens.[1] This expansion includes specific details about lighting, camera angles, composition, and material textures.[6][1] Because the model supports a native input of 1,000 tokens—far exceeding the roughly 77-token limit of earlier latent diffusion models—it can process highly complex, multi-paragraph instructions without losing semantic alignment. This capability is particularly apparent in the model’s "professional typography" mode, which can generate complex infographics, multi-panel comics, and even full presentation slides with accurate English and Chinese text rendering.
The model’s ability to handle text within images is a direct result of its Multimodal Scalable Rotary Positional Encoding (MSRoPE). This specialized encoding scheme jointly processes positional information for both text and image modalities, allowing the model to understand exactly where a specific word should be placed on a generated poster or billboard. In industry benchmarks and human evaluations, this has placed Qwen-Image-2.0 at the forefront of the "text-rich" generative category.[1] The model does not just treat text as a visual texture; it treats it as a structured element of the composition, maintaining legibility across diverse scripts and layouts.[7][1] This addresses one of the most persistent "hallucination" problems in the field, where AI models would historically generate garbled, unreadable characters.
Market performance and community reception further validate Alibaba’s technical choices. On LMArena, the prominent platform for blind human-preference testing, Qwen-Image-2.0 has secured the 9th position globally.[1] While this puts it slightly behind the absolute frontier models from OpenAI and Black Forest Labs in terms of raw artistic "vibe," it outperforms them in practical, instruction-following tasks and editing precision. Unlike many competitors that require separate models for generation and editing, Qwen-Image-2.0 is an "omni-capable" unified framework.[1] It uses a multi-task learning paradigm that integrates text-to-image, image-to-image, and instruction-based editing objectives within the same shared latent space.[1] This means the same model that creates a landscape can also be told to "change the season to winter" or "add a red car in the foreground" with high semantic consistency.[8]
The implications for the broader AI industry are profound. As the cost of compute remains a primary barrier to entry for many developers, Alibaba’s focus on 16x compression and 4-step generation provides a blueprint for making high-end AI more accessible.[1] The technical report details a multi-stage training curriculum—starting from low-resolution previews and progressing to 2K high-resolution refinement—that suggests a more disciplined, data-centric approach to model development.[1] By releasing the technical details and ranking highly on open benchmarks, Alibaba is positioning the Qwen ecosystem as a viable, efficient alternative to the computationally heavy proprietary models of the West.[1]
Ultimately, Qwen-Image-2.0 is less about the pursuit of the "perfect" artistic image and more about the mastery of the generative pipeline.[1] It is a model designed for the reality of the 2026 AI landscape: a world that demands speed, accuracy, and the ability to follow incredibly long, complex human instructions.[1] By solving the bottlenecks of typography, training stability, and inference latency, Alibaba has moved the needle on what a foundational image model is expected to do.[1] The leap from 40 steps to four is not merely a technical curiosity; it is a signal that the era of slow, expensive AI generation is coming to a close, replaced by efficient, architectural innovations that bring the power of 2K synthesis to every desktop and mobile device.[1]
Sources
[1]
[2]
[3]
[4]
[8]