OpenAI’s New Science Test Reveals AI Can Master Experts But Fails Discovery.
The FrontierScience evaluation confirms AI mastery of structured logic, yet exposes a profound gap in real-world scientific inquiry.
December 18, 2025
The unveiling of OpenAI's new FrontierScience benchmark represents a pivotal moment in the evaluation of artificial intelligence capabilities, moving beyond traditional tests of factual recall to measure genuine expert-level scientific reasoning and research aptitude. This rigorous new framework, developed with the input of international science Olympiad medalists and PhD scientists, immediately positions OpenAI's in-house model, GPT-5.2, as the current leader in this emerging class of demanding evaluations, yet simultaneously exposes a profound and illuminating gap in the model's ability to handle ambiguous, real-world scientific inquiry. The benchmark's results offer a clearer roadmap for the future of AI-accelerated science, delineating where today's systems are ready to act as powerful research assistants and where the fundamental challenges of open-ended discovery still remain firmly in the human domain.
FrontierScience was explicitly designed to address the problem of benchmark saturation, where even prior expert-level science evaluations, such as the Google-Proof Question Answering (GPQA) test, have become less informative due to the rapid advancement of large language models. For instance, GPT-4 initially scored 39 percent on GPQA when it was introduced, but the newest GPT-5.2 model has since achieved an accuracy of 92 percent on that same benchmark, a clear indication that new, more challenging assessments were needed to track meaningful progress[1][2][3]. The new benchmark is split into two distinct tracks: FrontierScience-Olympiad, which consists of 100 highly constrained, theoretical questions at the difficulty level of international competitions in physics, chemistry, and biology; and FrontierScience-Research, which comprises 60 open-ended, multi-step research sub-tasks that mimic the complex problems PhD-level scientists encounter in their actual work[4][5][2][6]. The questions, numbering over 700 in total with a gold set of 160, were meticulously crafted by 42 international Olympiad medalists and 45 scientists with doctoral degrees to ensure both originality and high difficulty across domains from quantum electrodynamics to synthetic organic chemistry[1][2][7][6].
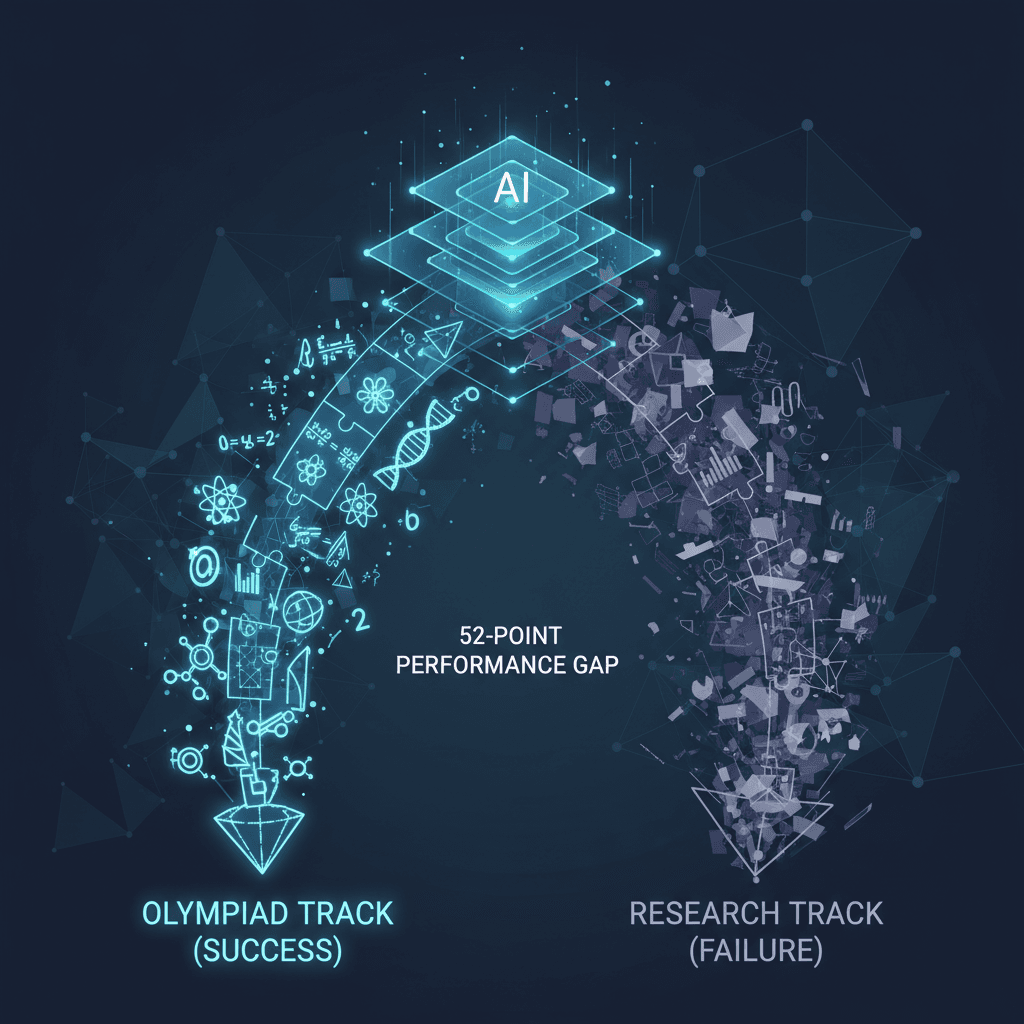
The initial performance data from FrontierScience paints a picture of substantial progress in structured reasoning, led by GPT-5.2, but also one of significant limitations when confronted with real-world ambiguity. In its initial evaluations, GPT-5.2 emerged as the top-performing frontier model, achieving a score of 77 percent on the FrontierScience-Olympiad track[4][8][5][7]. This score demonstrates an expert-level command of structured scientific problem-solving, where the problem has clear constraints and a single, verifiable solution, often expressed as an algebraic expression, single number, or unique term[2]. The model's success in this track suggests that modern AI systems are now capable of excelling at complex, deep-reasoning tasks that are typically the domain of the world's most gifted young scientists[7][3]. However, the model’s score dropped dramatically when faced with the open-ended challenges of the Research track, managing only a 25 percent success rate[4][8][5][7][9]. This stark, 52-point performance gap between the two tracks reveals what some analysts have termed the “ambiguity barrier,” highlighting that while AI is adept at following defined logical pathways, it struggles significantly with the messy, ill-defined, and multi-step nature of genuine scientific discovery[10][7][9].
The challenges presented in the FrontierScience-Research track are representative of the grunt work and deep conceptual synthesis that characterize doctoral-level investigation, with some tasks estimated to take human experts several days of computer simulations or weeks of complex mathematical derivation[7]. This track's unique evaluation method—a granular, 10-point rubric-based system used to grade intermediate steps and the quality of reasoning, rather than just the final answer—is central to understanding the limitations revealed[1][10][7]. Analysis of the model's failures indicated common issues such as reasoning, logic, and calculation errors, a lack of understanding of niche scientific concepts, and the generation of factual inaccuracies[10]. While the Olympiad questions require models to reason within a constrained space, the Research questions demand creativity, hypothesis generation, and the ability to synthesize ideas across disparate fields—capabilities that are currently proving far harder to automate[1][6][3].
The launch of FrontierScience and the concurrent performance data have profound implications for the entire AI industry and the future of scientific research. The strong performance on the Olympiad track confirms that AI systems can already accelerate the structured parts of scientific workflows, such as literature review, complex mathematical proofs, and data analysis, potentially compressing tasks that once took days or weeks into mere hours[5]. This positions current AI models as invaluable practical research assistants for the more defined aspects of an investigation[5][9]. However, the low score on the Research track serves as a crucial reality check, underscoring that the pursuit of Artificial General Intelligence, capable of independent, creative scientific discovery, remains an ongoing endeavor[3]. Industry insiders and researchers agree that for AI to transition from a sophisticated search engine to a genuine research collaborator—a system that can multiply a scientist's progress—it will need to significantly close that 52-point gap on open-ended problems[7][11][3]. The benchmark is not an endpoint, but a catalyst, offering clear signals to developers on the specific failure modes—reasoning errors versus knowledge gaps—that need to be addressed in the next generation of models, guiding focused effort on improving scientific capabilities and accelerating AI’s evolution into a truly autonomous partner in scientific breakthroughs[5][10].
Sources
[1]
[3]
[4]
[7]
[9]
[10]
[11]