Meta Releases DINOv3: Universal Vision AI Learns Without Labels, Boosts Adoption
Meta's DINOv3 redefines AI vision with unprecedented self-supervised learning, democratizing powerful tools for all industries.
August 17, 2025
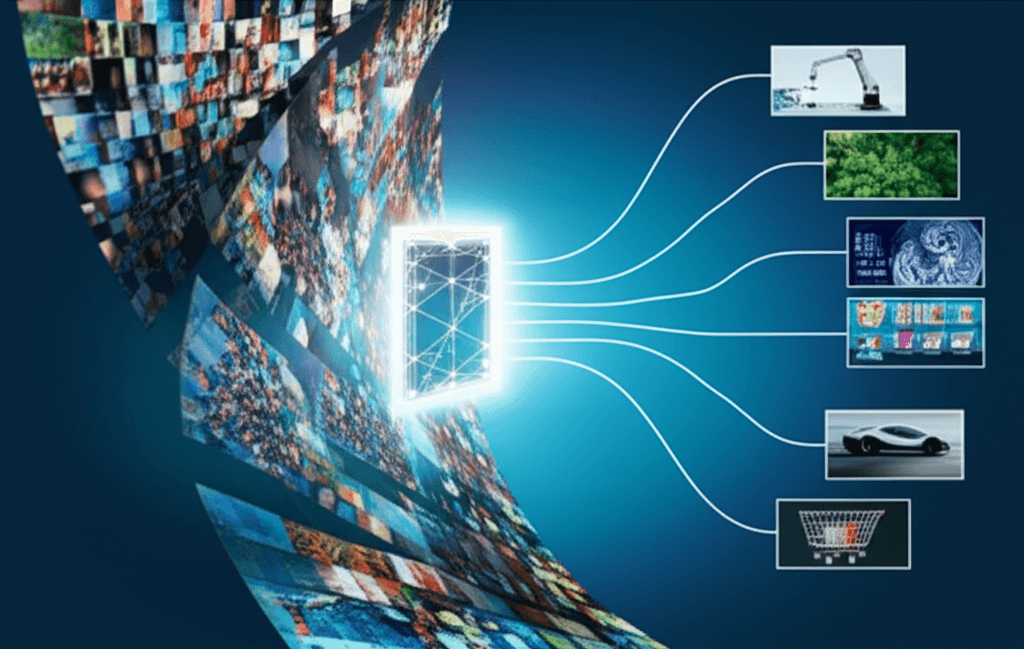
Meta has released DINOv3, a state-of-the-art computer vision model, making it available under a commercial license in a move set to accelerate the adoption of advanced artificial intelligence across numerous industries.[1] This new model represents a significant breakthrough by scaling self-supervised learning to an unprecedented level, effectively teaching itself to understand images without the need for manually labeled data.[2][3][4] The release provides businesses and developers with a powerful, universal tool for image analysis that could reshape the competitive landscape of AI and lower the barrier to entry for sophisticated visual intelligence applications.[1][5] By offering a complete suite of pre-trained models, code, and adapters, Meta is not just advancing the technological frontier but also challenging the closed-source business models of competitors like Google and OpenAI.[6][7]
The core innovation behind DINOv3 lies in its mastery of self-supervised learning (SSL), a method that has long promised to solve one of AI's biggest bottlenecks: the reliance on vast, human-annotated datasets.[2] Traditional model training is a costly and time-consuming process, but DINOv3 learns visual representations directly from raw, unlabeled images.[4] Meta has pushed this technique to a new scale, training DINOv3 on a massive dataset of 1.7 billion images with a model containing 7 billion parameters, a 12-fold increase in data and a 7-fold increase in model size compared to its predecessor, DINOv2.[4][8] This immense scale results in a "universal vision backbone" that produces powerful, high-resolution features capable of understanding images at a granular, pixel-level.[2][9] For the first time, a single, all-purpose vision model with a "frozen backbone"—meaning its core weights do not need to be fine-tuned for specific jobs—has been shown to outperform specialized, task-specific models in complex areas like object detection, semantic segmentation, and video tracking.[2][3][10] This versatility allows developers to train lightweight, efficient adapters for new tasks, drastically reducing the time and computational resources typically required to deploy a new vision application.[2][8]
The decision to provide DINOv3 under a commercial license carries profound implications for the AI industry, effectively democratizing access to cutting-edge computer vision capabilities.[1][5] This move is aligned with Meta's broader strategy of making its powerful AI models freely available for commercial use, a tactic that pressures competitors and fosters a wide ecosystem of developers building on its technology.[6] By open-sourcing the entire DINOv3 suite, including various model sizes and architectures to suit different needs from large-scale servers to resource-constrained devices, Meta is enabling businesses of all sizes to integrate advanced AI into their operations.[3][4] The global computer vision market is projected to grow significantly, and DINOv3's release is poised to accelerate this trend by opening up new business opportunities.[1] Industries such as manufacturing can leverage the model for enhanced quality control, while e-commerce platforms can build more sophisticated visual search and recommendation engines.[1] Further applications are expected to emerge in healthcare for diagnostic imaging, in agriculture for crop monitoring, and in the development of autonomous vehicles.[1][2]
Beyond its potential business applications, DINOv3 is already demonstrating a tangible impact on real-world challenges where data labeling is impractical or impossible.[8] The World Resources Institute (WRI) is utilizing the model to analyze satellite imagery for monitoring deforestation and supporting ecosystem restoration efforts.[2][4] The results have been transformative; compared to DINOv2, the new model reduced the average error in measuring tree canopy height in a region of Kenya from 4.1 meters to just 1.2 meters.[2][8][10] This leap in accuracy helps automate the verification of restoration outcomes, accelerating the flow of climate finance to local conservation projects.[2][10] In another high-stakes environment, NASA's Jet Propulsion Laboratory is using DINOv3's technology to build more capable exploration robots for missions on Mars, where efficient visual understanding is critical and computational resources are minimal.[4] These examples underscore the model's ability to unlock new frontiers in science and environmental monitoring, fields previously hampered by the sheer volume and complexity of visual data.[2]
In conclusion, Meta's release of DINOv3 for commercial use marks a pivotal moment for the field of artificial intelligence. It establishes a new state of the art for computer vision, proving that self-supervised learning can produce generalist models that outperform their specialized counterparts without the need for costly human supervision.[2][11] This technological achievement is matched by its strategic significance; by providing powerful AI tools openly, Meta is fostering widespread innovation and challenging the prevailing business models in the AI sector.[6] While this move concentrates the ability to train such massive foundational models within a few well-resourced organizations, it also distributes the power to apply them more broadly than ever before.[5] As developers and businesses begin to integrate DINOv3 into their products and services, the full impact of this powerful, label-free vision model will unfold across countless industries, accelerating the ongoing transformation driven by artificial intelligence.
Sources
[2]
[5]
[6]
[8]
[9]
[10]
[11]