Karpathy declares LLM startups must master four application functions to win.
Andrej Karpathy's four steps for startups to build an indispensable application moat atop commoditized LLMs.
December 23, 2025
The explosive growth of large language models (LLMs) and the dominance of labs like OpenAI, Google, and Anthropic have created an existential question for the application-layer AI startup: how can they compete when their core intelligence is essentially a commodity service? According to Andrej Karpathy, the former head of AI at Tesla and a founding member of OpenAI, the answer is not to try and build a better foundational model but to specialize and build a sophisticated application layer that orchestrates the underlying intelligence for specific, high-value tasks. Karpathy's perspective is deeply informed by his experience at the frontier of AI research and deployment, from leading the Autopilot vision team at Tesla to his role in the development of the GPT models at OpenAI, where he also built a team focused on mid-training and synthetic data generation.[1][2] He posits that a new category of "LLM apps" is emerging, and he uses the AI-powered code editor, Cursor, as a prime example that "convincingly revealed a new layer" of AI application development, leading to the new paradigm of "Cursor for X."[3]
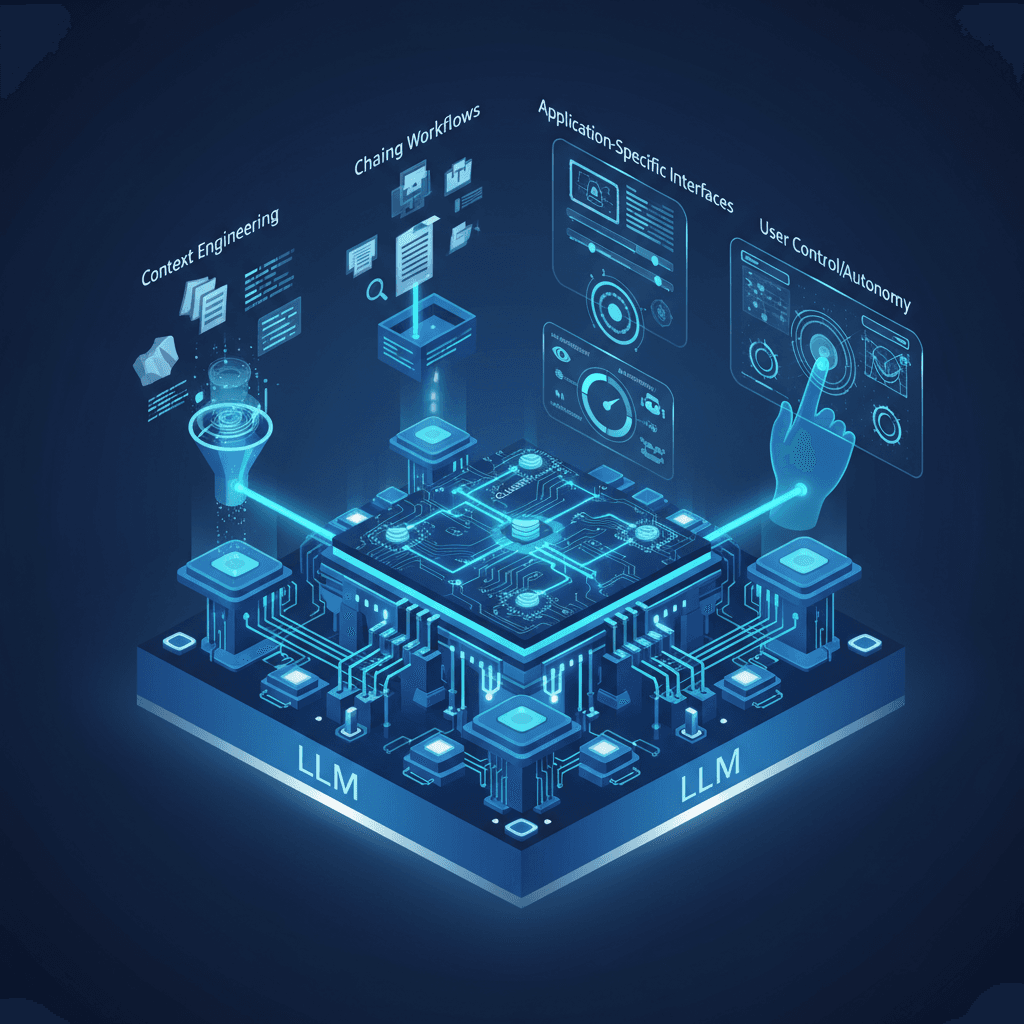
Karpathy identifies four core functions that these successful, specialized LLM applications must master to differentiate themselves from simple wrappers and establish a sustainable competitive advantage, or "moat." The first critical function is *context engineering*, which involves the app taking on the strenuous but vital work of preparing and structuring the context fed to the language model.[3] In the era of LLMs, the performance and relevance of the output are heavily dependent on the quality and specificity of the input context. Rather than relying on a user to craft an intricate prompt, a successful application will programmatically assemble all necessary external information—such as proprietary documentation, relevant code snippets, historical user data, or current enterprise policies—and feed it to the model.[4] This moves the difficult work of information retrieval and formatting away from the end-user and into the application's underlying logic, dramatically improving the utility and reliability of the AI's output for a specific domain.
The second key function for a successful LLM application is *chaining multiple LLM calls into complex workflows*. A sophisticated AI application rarely relies on a single, isolated call to a language model's API. Instead, it must serve as an orchestrator, breaking down a user's high-level request into a sequence of smaller, manageable steps. This process may involve multiple interactions with the LLM, external tools, and proprietary databases.[3] For instance, a finance application might use a language model to first classify a transaction, then query an internal ledger system, use the model again to generate a draft report summary, and finally pass that draft to a third-party compliance checker. This chaining of calls is where the startup's unique domain expertise is codified into the product's logic, creating a valuable, bespoke system far beyond what a general-purpose chatbot can offer. Karpathy's view aligns with the sentiment that LLMs are the "kernel of a new operating system," and the application layer's job is to build the "user space," which encompasses the user interface, the logical flow, and the data plumbing that makes the entire workflow function.[4]
The third and fourth functions center on the human-computer interaction necessary to transition from a general-purpose AI utility to a focused, indispensable product. The third function is providing *application-specific interfaces*. This is about moving beyond the simple chat-window interface and designing a user experience tailored to the specific problem being solved. For a coding assistant, this means deeply integrating the AI into the IDE; for a legal research tool, it might mean specialized visualization and annotation layers for document comparison. Karpathy suggests that effective AI tools are more like an "Iron Man suit," augmenting human capabilities rather than fully replacing them.[5] This collaborative AI approach focuses on using the AI for "heavy lifting" while preserving "human judgment, oversight, and verification for critical tasks."[5] By creating an interface that is purpose-built, the startup can leverage the model's power in a way that feels native and intuitive to a specialized user base, such as a developer engaging in the modern style of "vibe coding," where natural language expresses intent and the AI generates the underlying code.[6]
The fourth core function is allowing *users to control their own level of AI autonomy*. This is a critical design choice in the shift towards partially autonomous, practical products. A startup should provide fine-grained controls over how much the AI acts independently versus when it requires human confirmation, ensuring the user maintains a sense of control and accountability.[3] In high-stakes environments, such as legal or medical fields, this control is not merely a feature but a requirement for adoption, as it manages the risk associated with AI "hallucinations" or inaccuracies. This focus on "human-in-the-loop" design provides a pathway for enterprises to safely integrate generative AI into their workflows, solving the practical challenges of governance and reliability that are essential for long-term survival in the enterprise market. Karpathy’s overall advice is clear: startups cannot win by trying to build a better foundational model than the well-capitalized major labs. Instead, their success will be determined by their ability to become indispensable specialists for vertical markets, building differentiation through proprietary data, specialized tools, and robust real-world feedback loops.[3]
Karpathy’s philosophy underscores a broader industry shift: the real value in AI is increasingly consolidating at the application layer, not the model layer. While foundation model developers vie for computational dominance in a race to train ever-larger models, the application-focused startup has the opportunity to capture value by solving tangible, "boring" problems for specific users who are struggling with documentation or repetitive tasks.[4] This differentiation—built through superior context engineering, complex workflow orchestration, domain-specific interfaces, and adjustable autonomy—is what creates the "sticky scaffolding" and data moats necessary to thrive in an ecosystem where the underlying LLM capabilities are rapidly becoming commoditized.[7] The message to AI entrepreneurs is a strong mandate to focus on the unique pain points of a niche, transforming a general-purpose intelligence into a specialized, high-impact solution.