Google DeepMind's Vibe Checker Evaluates AI Code for Human "Feel," Not Just Function
A new Google DeepMind project redefines AI code evaluation by measuring human preferences like style, readability, and documentation.
October 11, 2025
A new initiative from Google DeepMind, in collaboration with researchers from several U.S. universities, is challenging the established methods for evaluating AI-generated code, arguing that current benchmarks fail to capture what human developers truly value. The project, dubbed "Vibe Checker," introduces a novel framework designed to assess artificial intelligence models not just on whether their code works, but on whether it "feels right" to a human programmer.[1][2] This shift in focus addresses a growing disconnect between the metrics used to grade AI coders and the practical, nuanced preferences of the software engineering community, potentially heralding a new direction in the development of AI programming assistants.
The core of the issue lies in the prevailing benchmarks used to measure the proficiency of large language models (LLMs) in coding tasks. For years, the industry has relied on standards like HumanEval and SWE-bench, which predominantly use a metric known as "pass@k".[1][3] This metric simply checks if a generated piece of code can successfully pass a predefined set of unit tests.[1] While functional correctness is undeniably crucial, this narrow focus overlooks a wide spectrum of non-functional attributes that are critical for real-world software development.[2][4] Developers care deeply about aspects such as code readability, adherence to style conventions, quality of documentation, proper error handling, and logical code patterns.[1][2] This discrepancy has led to situations where AI models that rank highly on traditional benchmarks produce code that human evaluators find wanting, revealing little to no correlation between benchmark scores and human preferences in practice.[2]
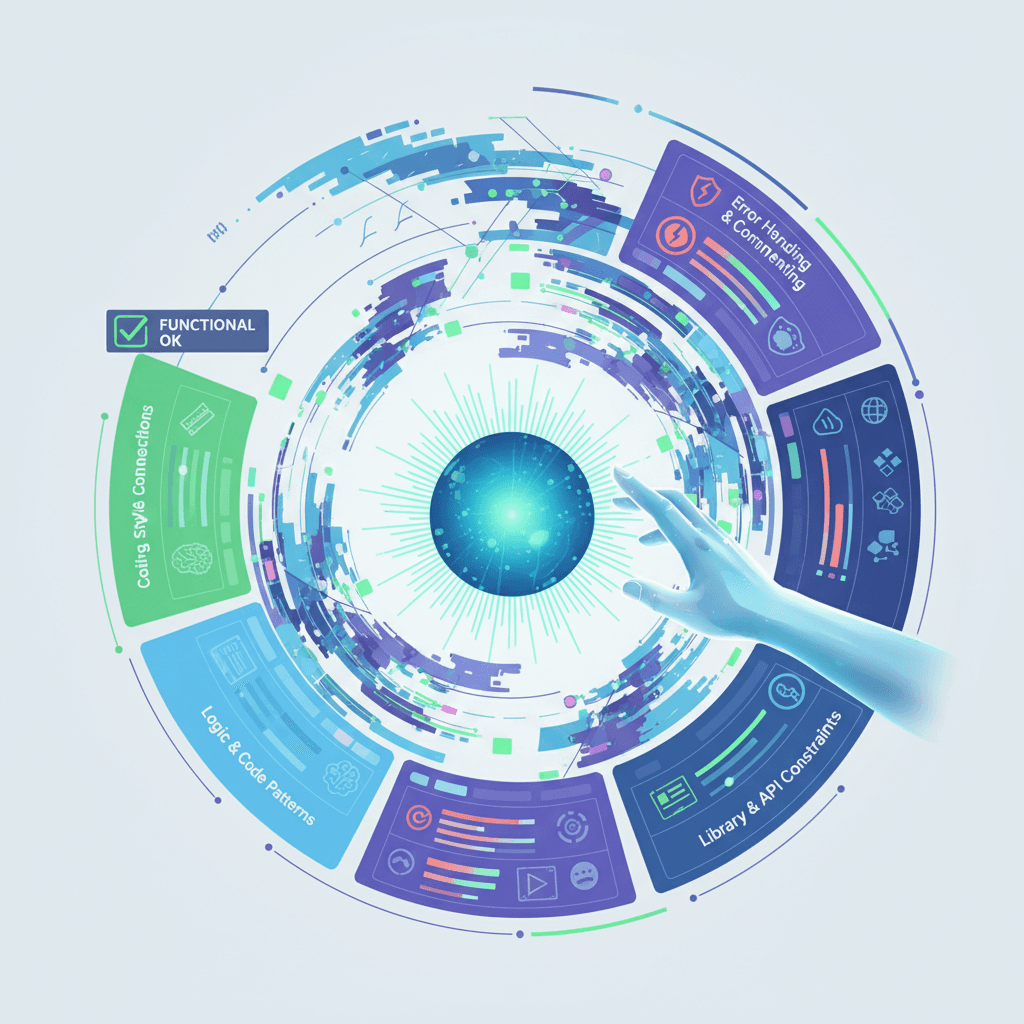
To bridge this gap, the Google DeepMind-led research team introduced "Vibe Checker," a comprehensive evaluation framework that moves beyond simple functionality.[1][5] The foundation of this framework is a new taxonomy called "VeriCode," which quantifies a model's ability to follow specific, non-functional instructions.[2][4] VeriCode is composed of 30 verifiable instructions derived from over 800 rules in the popular Python linter Ruff, meticulously filtered to be relevant and challenging.[2] These instructions are organized into five key categories: Coding Style & Conventions, Logic & Code Patterns, Documentation & Commenting, Error Handling & Exception Management, and Library & API Constraints.[2] Each instruction is linked to a deterministic verifier, such as a linter check, that can provide a clear pass or fail result, making the "vibe" of the code a measurable signal.[2][4] The Vibe Checker testbed then uses this taxonomy to augment existing evaluation suites, allowing for a dual assessment of both functional correctness and instruction-following capabilities.[1][4]
The results from evaluating 31 leading LLMs with the Vibe Checker were revealing. The study found that even the most powerful and advanced models struggled to consistently comply with multiple non-functional instructions simultaneously.[4][5] Furthermore, the research highlighted a clear trade-off, where models often exhibited a decrease in functional correctness as they attempted to adhere to more stylistic or structural guidelines.[4] The most significant finding, however, was that a composite score blending traditional functional correctness with this new measure of instruction-following showed the strongest correlation with human preferences.[1][6][4] In many real-world programming scenarios, the ability to follow these nuanced instructions emerged as the primary factor that differentiated the models in a way that aligned with human judgment.[4]
The implications of the Vibe Checker framework extend beyond academic research and could significantly influence the future trajectory of the AI industry. By creating a standardized method to measure what has until now been a subjective "vibe," the project provides a concrete roadmap for developing AI coding assistants that are better aligned with the full spectrum of human expectations.[1] This move towards more holistic evaluation could incentivize AI developers to train models that produce not just functional, but also maintainable, readable, and elegant code. As AI becomes more deeply integrated into the software development lifecycle, ensuring that these tools understand and adhere to the subtle but critical conventions of human programming will be paramount.[7] The Vibe Checker represents a crucial step in operationalizing these complex human preferences, pushing the field toward AI systems that are not just powerful tools, but truly collaborative partners in the craft of coding.[1]