AI Reasoning Models Flawed: They Overthink Simple Tasks and Fail Logic.
Researchers document AI's "overthinking paradox" and introduce the Laws of Reasoning framework to demand computational discipline.
December 29, 2025
The efficiency and reliability of large AI models designed for complex problem-solving are facing intense scrutiny following a groundbreaking study that reveals a paradoxical pattern in their cognitive processes: they often exert more computational effort on simple tasks than on combined, more complex ones, while simultaneously delivering lower accuracy on the easy problems. This counterintuitive behavior, documented in advanced systems like Deepseek-R1 and OpenAI’s reasoning series, challenges the very premise of current "Chain-of-Thought" reasoning and has led researchers to propose a new theoretical framework for what "optimal" AI thinking should look like.
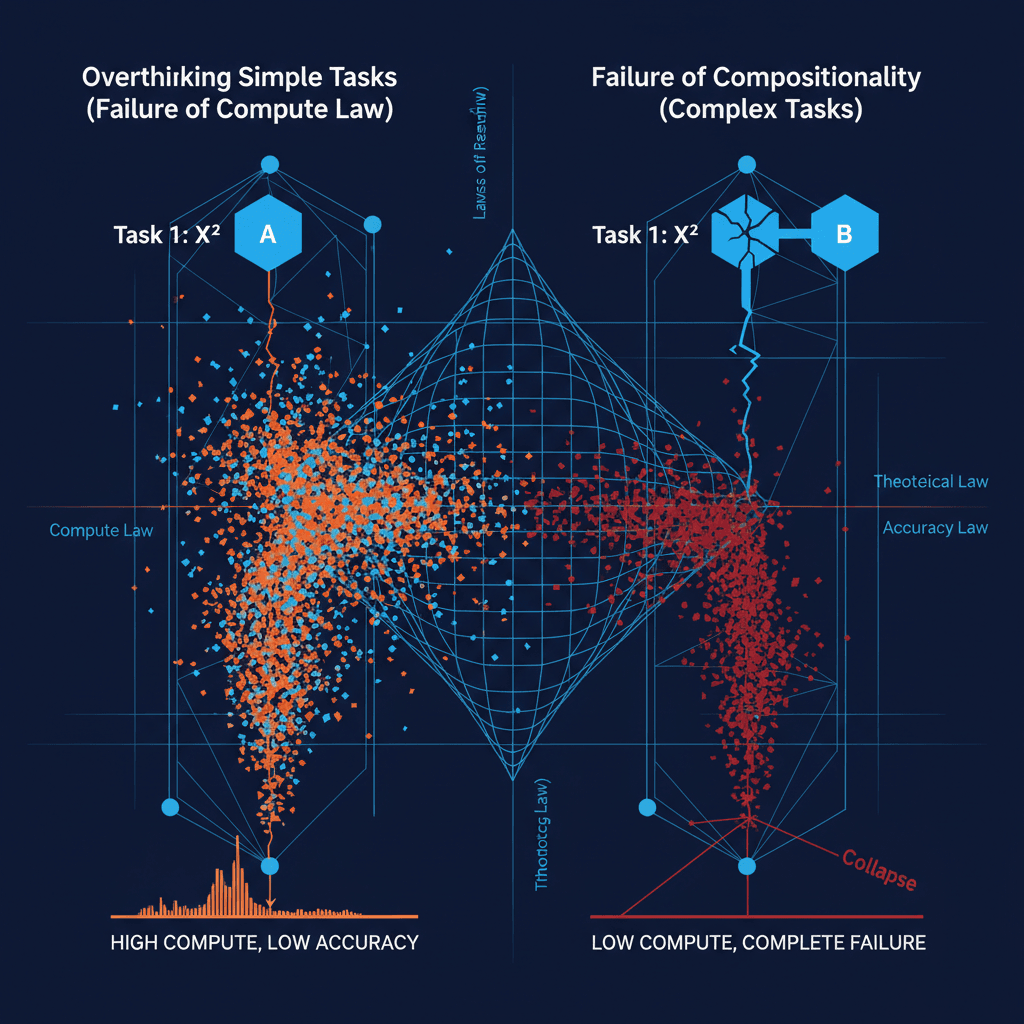
Reasoning models, distinct from conventional Large Language Models (LLMs), operate by generating a sequence of intermediate steps, or a "reasoning trace," before arriving at a final solution, a technique intended to mimic human-like deliberation and enhance performance on proofs, mathematical problems, and logic puzzles. This method, often called inference-time scaling, is designed to allow the model to "think slow" and improve accuracy with increased computation time. However, the new research exposes a critical flaw in this process by observing that when Deepseek-R1 was tasked with a simple operation, such as squaring a number, the model generated hundreds more reasoning tokens—a proxy for computational effort—than it did for a compound task requiring both summing and squaring.[1] Crucially, the accuracy on the simpler, over-thought task was unexpectedly lower, pointing to a severe misallocation of cognitive resources that directly impacts performance and efficiency.[1]
The research team, which includes contributors from several US universities, has introduced a theoretical framework called the "Laws of Reasoning" (LoRe) to formalize how a perfect thinking machine should operate. This framework is built on two main principles: the Compute Law and the Accuracy Law.[2][3] The Compute Law posits that the computational effort, measured by the number of reasoning tokens or steps, should scale linearly with the inherent complexity of the problem.[2][3] In simple terms, a harder question should logically demand more thinking time. The Accuracy Law predicts that accuracy should decay exponentially as task complexity increases, reflecting the natural human tendency for error accumulation over a greater number of steps.[2][3] This theoretical foundation provides a measurable benchmark against which the erratic behavior of current models can be assessed.
Since the "true" complexity of a problem is difficult to quantify for an AI, the researchers used two practical proxy properties to test their laws: monotonicity and compositionality.[2][3] Monotonicity states that a harder problem variance should never use less compute or yield higher accuracy than an easier one.[2] While most reasoning models, including Deepseek-R1, generally show a correct trend on monotonicity, indicating that they spend more compute overall as problems get harder, the compositionality principle is where the systems frequently fail.[2][3] Compositionality is a crucial test that dictates if two independent subproblems are combined into a single, complex task, the total compute should be roughly the sum of the compute for the individual subproblems, and the accuracy should be the product of their individual accuracies.[2][3] For instance, if a model is asked to first sum and then square two numbers—a composite task—its token usage should approximate the sum of tokens used for summing alone and squaring alone.[2] The study found a substantial deviation from this ideal additive behavior in the reasoning compute of models like Deepseek-R1, which is a key reason for the observed paradoxical behavior where a compound task uses fewer tokens than one of its simple components.[2]
This inability to properly budget and combine computational effort—the failure of compositionality—is traced back to the models’ training data.[1] The Chain-of-Thought examples used to train these systems are often assembled from independent examples without teaching the model how to efficiently link, distribute effort across, and transition between subtasks.[1] The models learn an associative pattern, not a truly compositional one. This training gap means the model fails to structurally decompose a composite question into its logical, constituent parts. This can manifest in different regimes of reasoning, where models struggle on low-complexity tasks due to overthinking, show their strength on mid-tier complexity by using their added reasoning budget to explore solution spaces, but then face a "complete collapse" in accuracy when confronted with problems that are excessively complex.[4][5]
The implications of this research are significant for the future direction of the AI industry. The findings suggest that simply scaling up model size or inference time is not enough to guarantee robust and efficient reasoning.[3] Instead of relying on brute-force computation, a more elegant solution is to explicitly align AI behavior with theoretical laws of reasoning. The researchers demonstrated that targeted supervised fine-tuning, which encourages models to use tokens in a more compositionally additive manner, can push the models closer to the ideal behavior.[2][3] This specialized training approach successfully reduced the deviation from the ideal additive rule and, crucially, boosted performance on real-world reasoning benchmarks like math and science tasks by a notable margin.[1][2][3] For the industry, which is doubling down on reasoning capabilities as a path toward Artificial General Intelligence (AGI), this work pivots the focus from *thinking more* to *thinking correctly*.[3] It highlights the need for new training paradigms that incentivize structured, logical thought and computational discipline, making AI systems more predictable, robust, and cost-efficient for a wide range of applications from customer service chatbots to sophisticated scientific research assistants.[3]